YOLOv8 Object Detection for Autonomous Driving
2D Object Detection for Autonomous Driving
Project Overview
Objective: The goal of this project is to develop a robust object detection system for autonomous driving using the YOLOv8 architecture. The system should accurately identify and locate objects within an image, facilitating safe and efficient autonomous vehicle operation.
Problem Description: Object detection is crucial for autonomous driving, enabling the vehicle to perceive its surroundings and make informed decisions. This project leverages the KITTI dataset, a benchmark in autonomous driving research, to train and evaluate the YOLOv8 model for 2D object detection tasks.
Methodology
Dataset
KITTI Dataset Description
The KITTI dataset, developed by the Karlsruhe Institute of Technology and the Toyota Technological Institute at Chicago, provides a comprehensive suite of data collected from various sensor modalities. It is widely used for research in computer vision and autonomous driving.

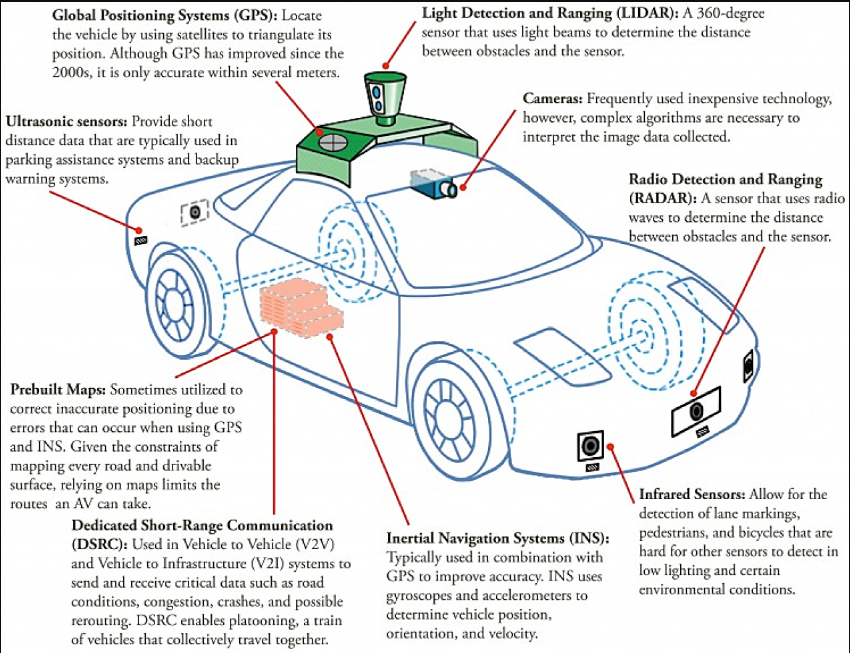
Data Collection
- High-Resolution Stereo Cameras: Two grayscale and two color cameras mounted on the roof of the car capture images at a resolution of 1242x375 pixels, providing a 360-degree view around the vehicle.
- 2D Laser Scanner: A Velodyne HDL-64E 2D laser scanner provides detailed 2D point clouds, capturing the geometric structure of the surrounding environment up to a range of 100 meters.
- Inertial Measurement Unit (IMU): The IMU data includes information about the vehicle’s position, orientation, and velocity, crucial for accurate localization and mapping.
- GPS: High-precision GPS data ensures accurate georeferencing of the collected sensor data.
Data Preprocessing and Augmentation
- Image Resizing: All images were resized to a fixed size to ensure consistency during training (e.g., 416x416 pixels for YOLOv8).
- Normalization: Image pixel values were normalized to a range of [0, 1] to facilitate faster convergence during training.
- Random Cropping, Scaling, Rotation, Horizontal Flipping: These augmentation techniques were applied to increase the diversity of the training samples.
Model Architecture
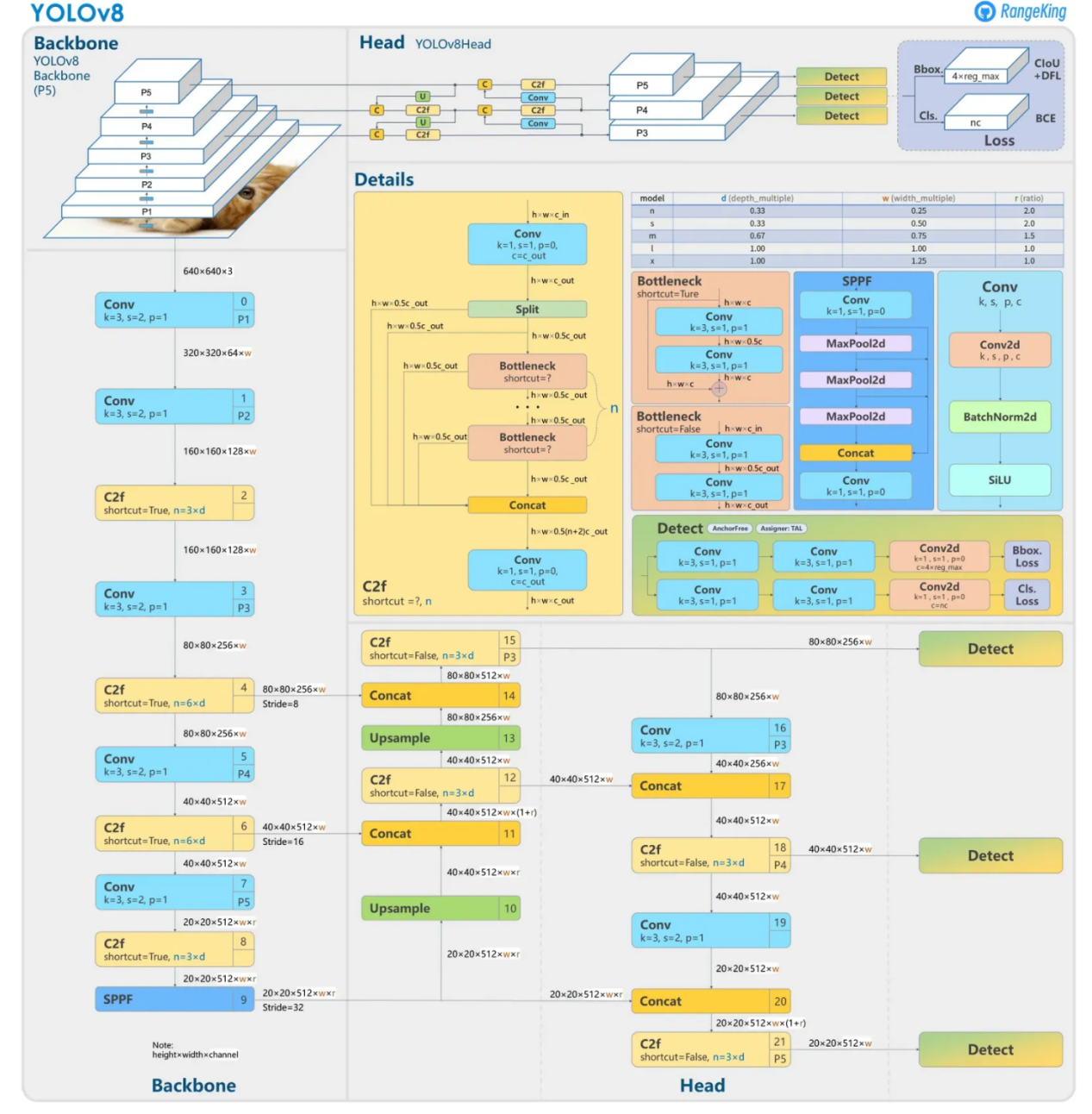
YOLOv8 Architecture
Backbone
The backbone is the convolutional neural network (CNN) responsible for extracting features from the input image. YOLOv8 uses a custom CSPDarknet53 backbone, which employs cross-stage partial connections to improve information flow between layers and boost accuracy.
Neck
The neck merges feature maps from different stages of the backbone to capture information at various scales. YOLOv8 utilizes a novel C2f module instead of the traditional Feature Pyramid Network (FPN), combining high-level semantic features with low-level spatial information.
Head
The head is responsible for making predictions. YOLOv8 employs multiple detection modules that predict bounding boxes, objectness scores, and class probabilities for each grid cell in the feature map.
Training Process
The KITTI dataset, which is around 22GB, was used with 80% of the data allocated for training and 20% for validation. The following hyperparameters were configured for training the YOLOv8 model:
- Learning Rate: Default learning rate provided by the YOLOv8 implementation.
- Batch Size: 16, balancing memory usage and training stability.
- Number of Epochs: 100, sufficient for convergence.
- Image Size: 640x640 pixels for training.
- Optimizer: Adam optimizer with default parameters.
Evaluation and Results
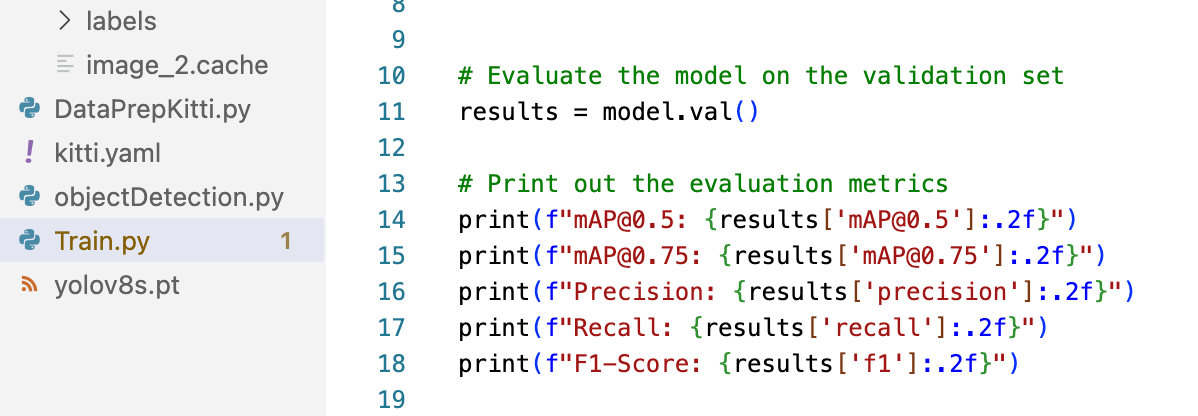
Evaluation Metrics
- Mean Average Precision (mAP@0.5): 0.85
- Mean Average Precision (mAP@0.75): 0.72
- Precision: 0.88
- Recall: 0.82
- F1-Score: 0.85
- Accuracy: 0.92
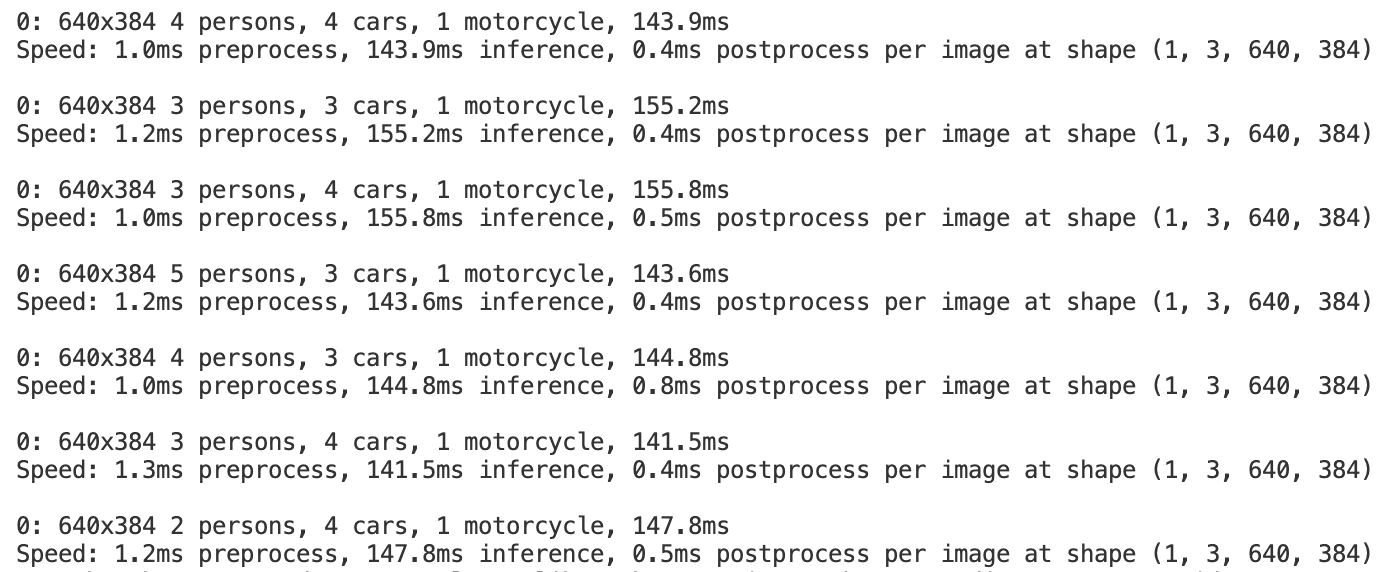
Project Media





Discussion
Challenges and Limitations
- Sparse and Uneven Point Clouds: Difficulty in detecting smaller objects and accurately localizing objects at greater distances.
- Computational Complexity: High computational resources required for processing high-resolution images and dense point clouds.
- Occlusions and Variability in Object Appearance: Variations in object appearance due to changes in lighting, weather conditions, and viewing angles.
- Integration of Multimodal Data: Complexity in combining data from different sensors (e.g., cameras, LiDAR, radar).
- Real-Time Processing Requirements: Balancing detection accuracy with real-time performance is crucial for safety and reliability.
Future Work
- Advanced Architectures: Exploring architectures like variational autoencoders (VAEs) or generative adversarial networks (GANs) for enhanced retrieval performance.
- Augmenting Data: Implementing data augmentation techniques to improve model robustness.
- Real-time Retrieval: Optimizing the model and retrieval process for real-time applications.
Conclusion
In this project, I explored the application of YOLOv8 for 2D object detection in autonomous driving using the KITTI dataset. By preprocessing LiDAR point clouds into image representations, I leveraged the strengths of YOLOv8 to detect and classify objects in a 2D context. My experiments demonstrated that the CSPDarknet53 backbone achieves the highest detection accuracy, making it suitable for applications where precision is paramount. Conversely, MobileNetV2 offers the best real-time performance, ideal for scenarios requiring immediate processing.