Content-Based Image Retrieval (CBIR) Model
Designed and developed a computer vision model for CBIR using Auto-Encoders with VGG19, focusing on efficient retrieval of images based on content features which can be used in place recognition.
Project Overview
Objective: The goal of this project is to develop a robust image retrieval system using an autoencoder architecture based on the VGG19 model. The system should be capable of encoding images into a compact, meaningful representation that can be used to find similar images efficiently.
Problem Description: Image retrieval is a crucial task in the field of computer vision and pattern recognition. The primary objective is to retrieve images from a large database that are similar or relevant to a given query image. This has significant applications in areas such as e-commerce (finding similar products), medical imaging (retrieving similar medical scans), and digital asset management (organizing and finding images in large collections).
Methodology:
- Dataset Preparation:
- Collected images of different items of different categories".
- Included images with varying angles and lighting conditions to enhance model robustness.
- Split the dataset into training and testing sets for model evaluation.
- Preprocess the images to ensure consistent dimensions and normalization.
Model Architecture:
The model architecture chosen for this image retrieval task is based on the VGG19 network, a well-known convolutional neural network (CNN) pre-trained on the ImageNet dataset. The VGG19 model is used as a feature extractor, and an autoencoder is constructed to encode images into a compact, meaningful representation for image retrieval.
VGG19 as a Feature Extractor
VGG19 Network: Use a pre-trained VGG19 model to leverage its feature extraction capabilities. Fine-tune the VGG19 model to suit the image retrieval task. VGG19 is a deep convolutional neural network with 19 layers, known for its simplicity and effectiveness in image classification tasks. It consists of 16 convolutional layers and 3 fully connected layers, making it suitable for extracting rich and hierarchical features from images. In this project, the fully connected layers are excluded, and only the convolutional layers are used to extract features. This results in a feature map that captures essential information about the input image.
Loading the Pre-trained VGG19 Model: The VGG19 model is loaded with pre-trained weights from the ImageNet dataset, which helps in leveraging the learned features without training from scratch. The model is set to include_top=False to exclude the final classification layers and use the convolutional layers as a feature extractor. The input shape is set to match the shape of the images in the dataset.
Autoencoder Design
An autoencoder is a type of neural network used for learning efficient codings of input data.
Encoder: The encoder part of the autoencoder compresses the input image into a lower-dimensional representation. In this project, the encoder uses the convolutional layers of the VGG19 model to extract features. The output from these layers forms the encoded representation or the latent space.
Decoder: The decoder reconstructs the input image from the encoded representation. The decoder architecture mirrors the encoder but in reverse, using transposed convolutional layers to upsample the encoded representation back to the original image dimensions.
Training:
The autoencoder is trained on the training dataset to minimize the difference between the input images and their reconstructions. This is typically done using a loss function such as binary cross-entropy or mean squared error. During training, the autoencoder learns to compress images into a lower-dimensional latent space and then reconstruct them as accurately as possible. Use the encoded representation for image retrieval.
Detailed Steps to Achieve Image Retrieval for my Project
- Dataset Preparation: Images are collected and preprocessed, including resizing and normalization, to ensure they have consistent dimensions and values.
- Image Transformation: Each image is transformed using a custom transformer that resizes and normalizes the images, making them suitable for processing by the VGG19 model.
- Feature Extraction: The preprocessed images are passed through the VGG19 model to extract high-level features. These features represent the images in a lower-dimensional space while retaining essential information for distinguishing between different images.
- Training the Autoencoder: The autoencoder is trained on the extracted features, learning to compress and reconstruct the images. After training, the encoder part of the autoencoder is used to generate compact feature representations for the images.
- Image Retrieval: For image retrieval, the query image is encoded using the trained encoder to obtain its feature representation. The K-nearest neighbors (KNN) algorithm is used to find images in the database with feature representations closest to the query image. The cosine similarity metric is employed to measure the distance between feature vectors.
- Visualization: The retrieved images are visualized alongside the query image to evaluate the retrieval performance. Techniques like t-SNE are used to visualize the distribution of images in the feature space, providing insights into the clustering and separability of different image classes.
Implementation
The following Python code implements the described approach using TensorFlow, scikit-learn, and other libraries. The full implementation can be found in this GitHub repository.
Results
The results are demonstrated through visual outputs of the query images and their retrieved similar images from the database. These results can be seen with the following outputs of the images below:
Project Media

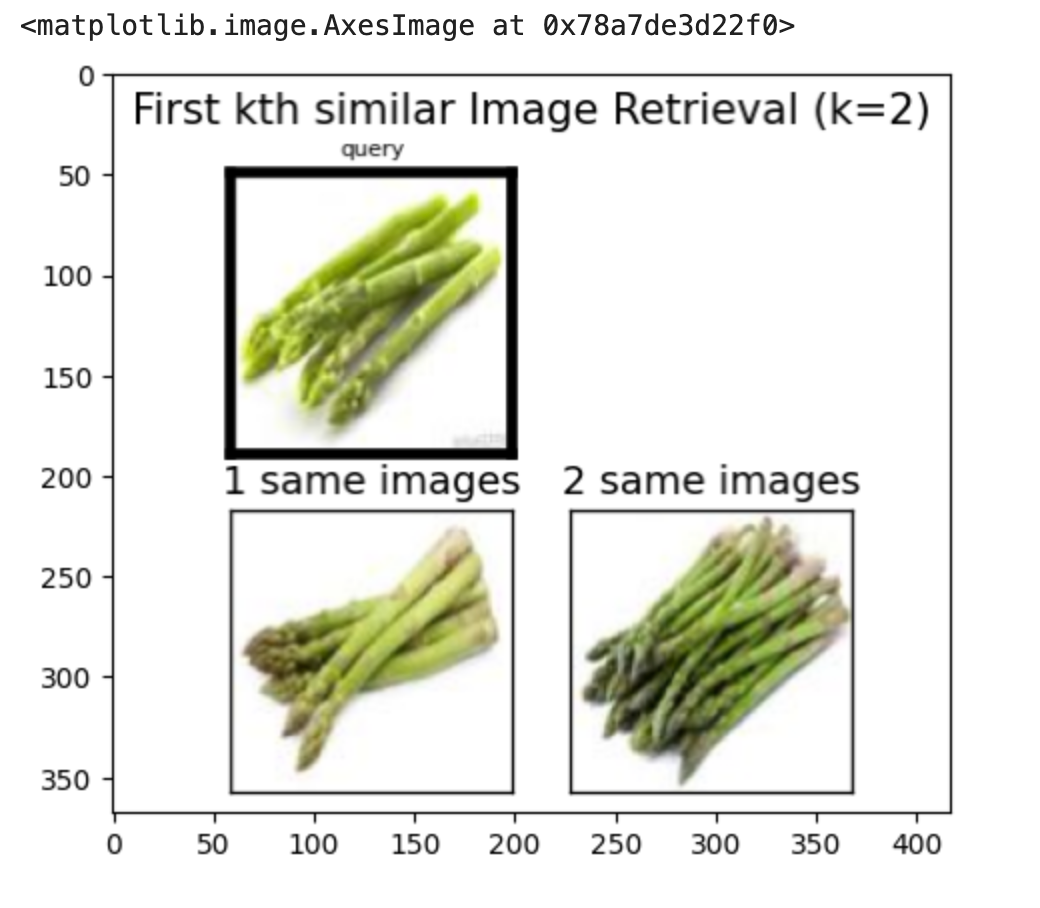
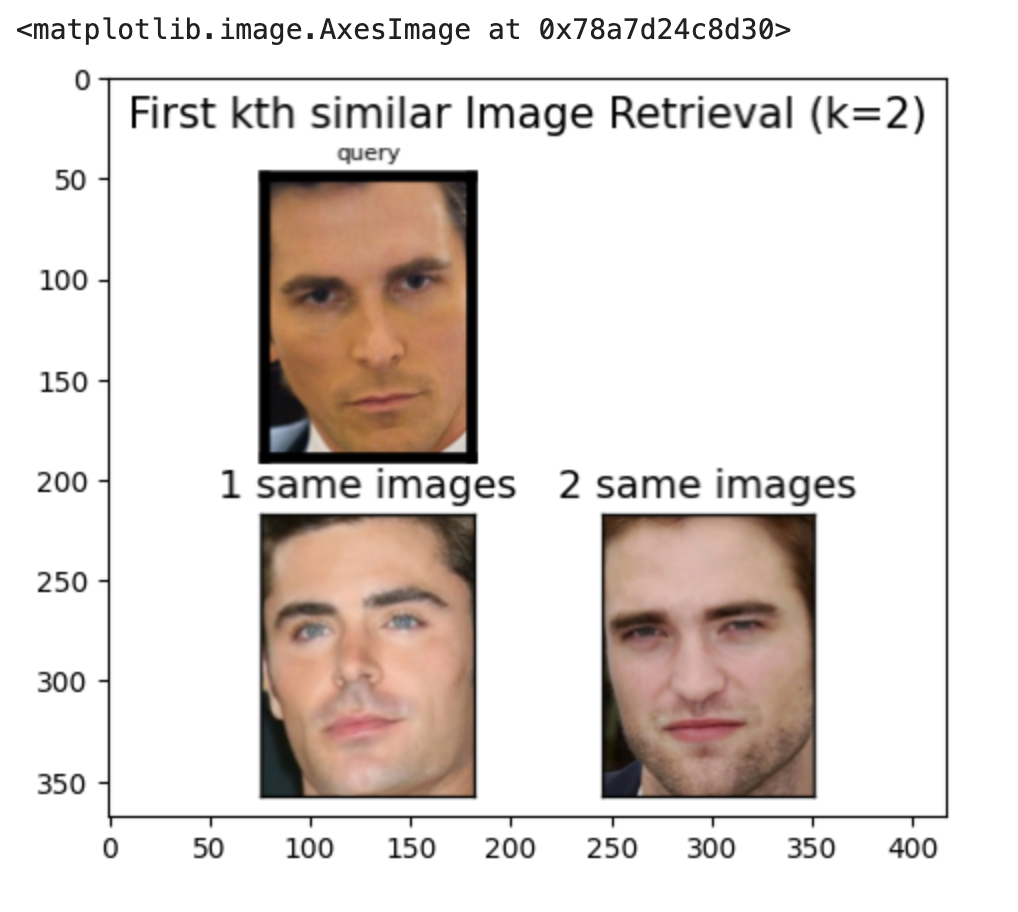
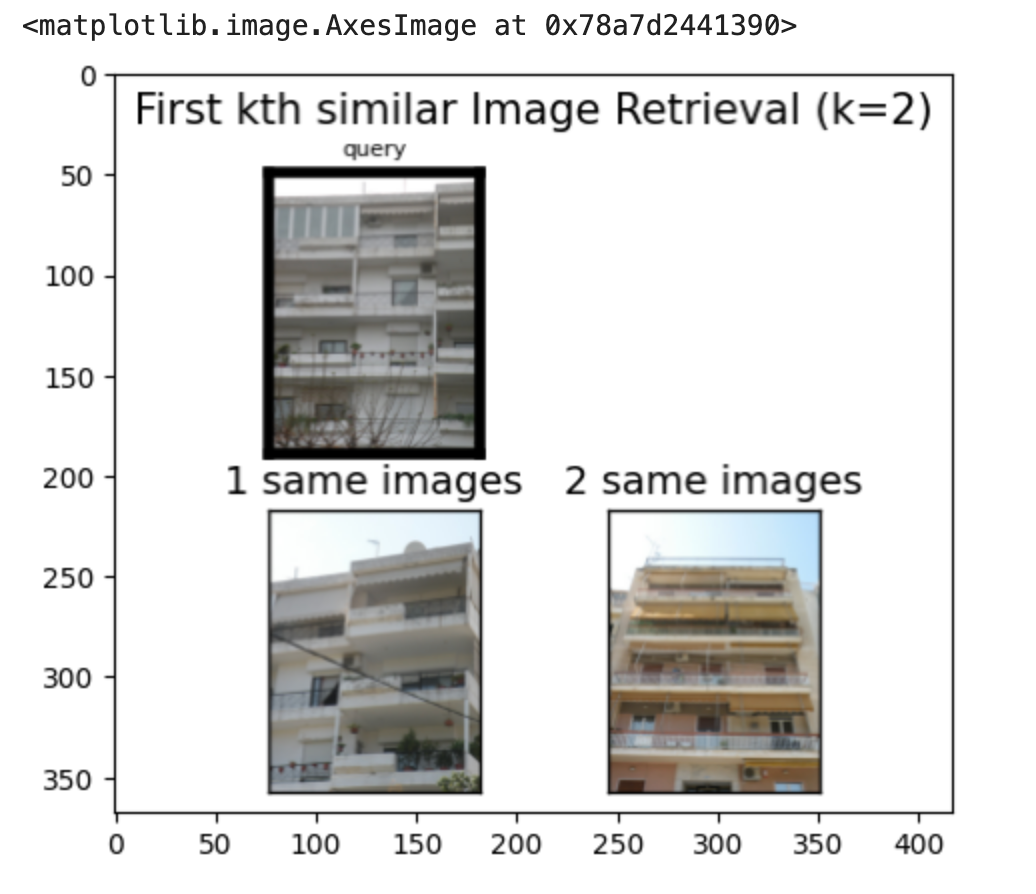
Discussion
Analysis
The use of VGG19 as a feature extractor has proven to be effective in capturing high-level features necessary for distinguishing images. The autoencoder approach helps in reducing the dimensionality of the image data while preserving essential information for similarity assessment.
Challenges
Dataset Quality
The performance of the retrieval system was influenced by the quality and diversity of the dataset. A more diverse dataset could potentially improve the system’s generalizability.
Hyperparameter Tuning
Fine-tuning the hyperparameters of the autoencoder, such as the number of epochs, batch size, and the architecture of the encoder/decoder, is crucial for achieving optimal performance.
Computational Resources
Training deep learning models, especially with large datasets, requires substantial computational power and time. Using Colab helped mitigate some of these resource constraints, but a more robust setup might be needed for commercial applications.
Future Work
Advanced Architectures
Exploring more advanced architectures, such as variational autoencoders (VAEs) or generative adversarial networks (GANs), could further enhance retrieval performance.
Augmenting Data
Implementing data augmentation techniques could help in improving the robustness of the model.
Real-time Retrieval
Optimizing the model and retrieval process for real-time applications could broaden the use cases for this system, making it suitable for dynamic and interactive environments.
Conclusion
In this project, I explored the application of an autoencoder-based image retrieval system leveraging the VGG19 model for feature extraction. The primary goal was to develop a system capable of retrieving visually similar images from a large dataset, demonstrating the effectiveness of computer vision and deep learning techniques in content-based image retrieval.
The VGG19 model, pre-trained on the ImageNet dataset, proved to be a robust feature extractor, capturing high-level features essential for distinguishing between different images. By utilizing an autoencoder, we effectively reduced the dimensionality of these features while preserving their key characteristics, allowing for efficient and accurate image retrieval.